
Why More Variations Tend To Backfire
When you test more than two variations, several things are happening simultaneously, and none of them are necessarily good for learning velocity.
Traffic gets spread thinner across more experiences. If you're running a standard A/B test with two variations, each gets 50% of your traffic. Add a third variation, and each gets 33%. Add a fourth, and you're down to 25% per variation. Instead of speeding up, you actually stall the experimentation velocity because each of those variations takes longer to accumulate meaningful, worthwhile data.
It takes longer to achieve statistical confidence. According to research on A/B testing statistics by CXL, underpowered experiments are one of the biggest reasons for test failures. Splitting traffic across too many variations reduces statistical power, removing your ability to detect real differences between your variations.
The more variations you add, it will require a larger sample size in order to maintain reliable confidence levels. Low-powered tests will likely give misleading conclusions and false negatives.
You’ll increase the risk of inconclusive tests. Instead of clarity, you could end up with more questions than answers. Often, inconclusive tests are misinterpreted due to insufficient sample size, implementing changes that hinted at a "trend" but never hit significance. That's not optimization. That's just adding more steps to guessing.
VWO's multivariate testing guide confirms this pattern: multivariate testing is most effective for high-traffic environments. Sites with lower traffic risk long test cycles and inconclusive results when their traffic is spread out across too many variations.
The only situation where adding more variations works favorably is when the site has high enough traffic volume that still allows you to reach a reliable confidence level in a reasonable timeframe. That would typically be two weeks or less.
When More Variations Actually Make Sense
Before you walk away thinking multi-variant testing is always wrong, we should clarify when it actually works. Context matters.
Testing two or more variations could make sense when:
Your traffic volume is high enough to reach significance quickly. If you've got tens of thousands of sessions per week going through the page you're testing, it’s safe to split traffic across multiple variations without damaging your test duration.
Your test hypothesis is tightly focused. Multi-variant testing works best if you're exploring variations of one single idea, rather than testing several different concepts against each other. Testing three headline angles that all address the exact same customer objection is much different from testing a new headline, a changed layout, and a change to pricing all at the same time.
Rather than minor tweaks, the variations are meaningfully different. If your variations are almost identical, the differences could be harder to detect, statistically speaking. Multi-variant tests need to include variations that are distinct enough to produce clearly measurable differences.
The business can manage longer testing cycles. Some tests are worth waiting a bit longer for. If the decision you need to make is high-stakes, and the variations represent significantly different strategic directions, a longer test cycle may be the way to go, if your business can support it.
For high-volume brands, simultaneously testing multiple strong concepts could reduce iteration cycles. But for most Shopify DTC brands, traffic tends to be the limiting factor. And when you have limited traffic, discipline takes priority over ambition.
The Real Power Of Multi-Variant Testing: Depth Over Width
Here's where multi-variant testing gets interesting, and where a lot of brands get it completely wrong.
Testing width (more variants) will never fix a weak idea. If the hypothesis is vague, or just not significant enough to matter, you're just spreading out traffic across multiple blind guesses. The result is more confusion, rather than any insight.
But testing depth, when you use multiple variations to explore a strong hypothesis from different strategic angles, you could turn one test into a mini, but meaningful learning opportunity. You're basing your tests on random guesses. Instead, you're stress-testing one good hypothesis across more than one sub-idea to learn what makes it work most effectively. And if you structure correctly, you’re more likely to move on from the experiment with your next iteration already defined.
"Complexity isn't sophistication," says Fernandes. "It's usually just noise with a nicer outfit."
The distinction is subtle but extremely crucial. Multi-variant testing actually works when the variations are directional, rather than completely random. Each one should test a specific lever while keeping your core hypothesis constant. If variation one emphasizes clarity, variation two should emphasize trust, then emphasize urgency for the third variation. You’ll not only learn which one performed best, but why.
When your variations are random permutations, lacking any strategic logic, attribution becomes more unclear. You may stumble on a winner, but you won't have a clear understanding of what made it win. That greatly limits your ability to build on the winning results.
AI Shortcut: Use ChatGPT or Claude to generate directional variation concepts from a single hypothesis.
Prompt example: "I'm testing whether adding social proof increases conversions on my product page. Give me three variation angles: one focused on trust signals, one on urgency, and one on specificity. Keep the core hypothesis the same but vary the psychological lever."
This ensures your variants are strategically distinct rather than randomly different.
Real Examples: Multi-Variant Testing That Produced Actionable Insights
Here’s how this plays out in real practice.
Example 1: Color Order Testing for a Hero Product
For one of our clients where one product represented the majority of their revenue, we discovered that user interactions with color options had a noticeably different impact on Net Revenue and AOV. The product had four color options, and we hypothesized that the order in which colors were displayed actually influenced users’ purchase behavior.
We tested different color orders across four variations:
The original showed Natural, Rustic, Walnut, and White.
Variation 1 reordered to Walnut, Natural, Rustic, and White.
Variation 2 tested Rustic, White, Walnut, and Natural.
Variation 3 displayed Natural, White, Walnut, and Rustic.
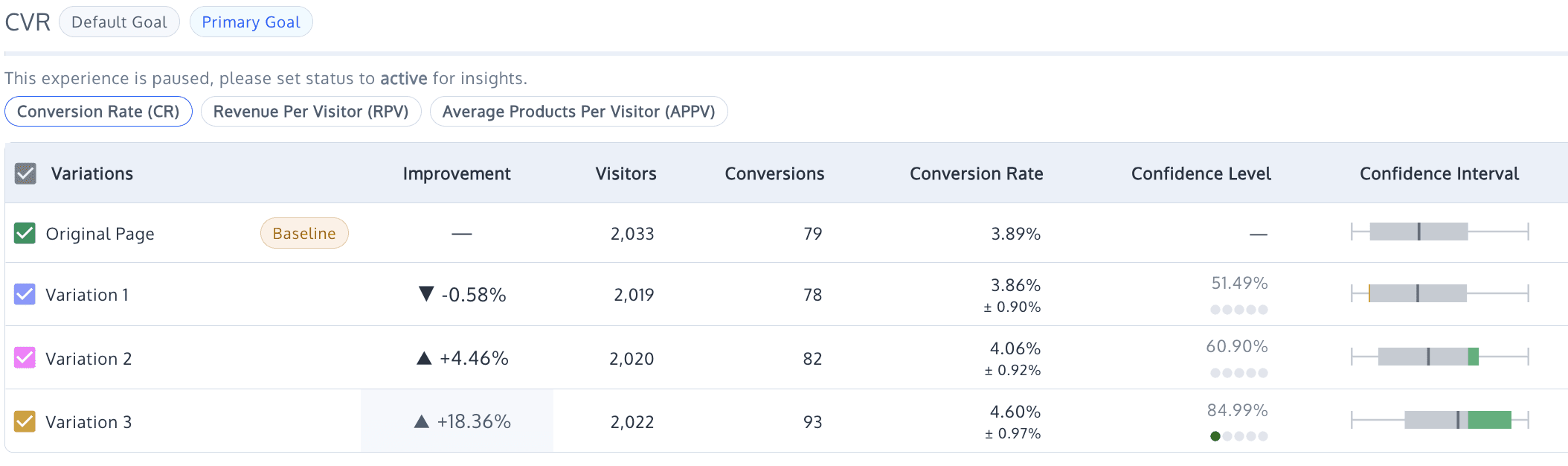
The results were surprising. Variation 1 showed a slight decrease in conversion rate at negative 0.58% but increased Checkout Started by 13.15%.
Variation 2 saw an improved conversion rate by 4.46% and Checkout Started by 47.33%.
Variation 3 achieved an increased conversion rate of 18.36% and a 72.06% increase in Checkout Started.
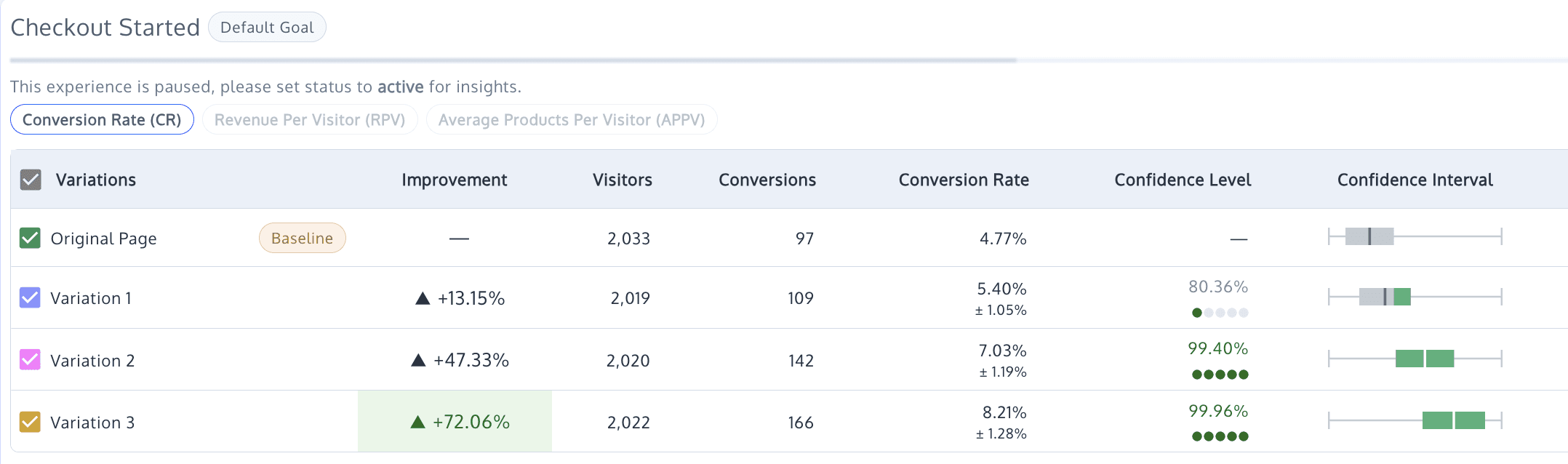
The results yield clear insights: since users saw specific product colors in ads, they went to the Product Page expecting to see that color prominently displayed.
By making the expected color more visually distinct and easier to select, we significantly reduced friction during the selection process, enhancing the overall user experience. One hypothesis, four variations, actionable insights about matching users with their expectations.
Example 2: Image Gallery Navigation Testing
For another client, we identified that their image gallery significantly impacted whether users purchased or not. Rather than testing completely different page layouts, we tested a few fairly subtle variations of the same element. We created multiple iterations within a single hypothesis and experiment.
We tested three variations of how their customers navigate and interact with their product images. The results were dramatically different for each one:
Variation 1 decreased conversion rate by 8.89% and revenue per visitor by 10.78%.
Variation 2 increased conversion rate by 11.02% and revenue per visitor by 15.85%.
Variation 3 decreased conversion rate by 15.91% and revenue per visitor by 6.92%.
We found that showing the exact number of images in their gallery allowed users to navigate and select products more effectively. The test proved our hypothesis was correct about the image navigation being a high-leverage element, while it simultaneously showed us precisely which approach worked best.
"Two sharp variations beat four weak guesses—every time," observed Fernandes.
Both examples shared a common structure, with a strong hypothesis, variations that explored the hypothesis from different angles, and an adequate amount of traffic to allow each test to reach meaningful conclusions. The multi-variant structure didn't impede our learning… in fact it accelerated it by compressing what would have been sequential tests into a single, more comprehensive experiment.
The Statistical Reality: Power Matters More Than Volume
Clearly understanding statistical power is absolutely essential for deciding how many variations you should run.
Statistical power is what determines your ability to detect real differences between the variations you test. According to research done by CXL on statistical power, the more variations you introduce, the larger the sample size you’re going to need to effectively maintain reliable confidence levels. Low-powered tests will just increase false negatives, presenting you with situations where a real improvement exists but you completely fail to detect it.
Here's the practical implication. If you simply don't have enough traffic to power that multi-variant test properly, you're not being thorough. You’re wasting resources, without any incoming benefits. You'll either waste time and opportunity cost on running the test too long, or call it early without getting any reliable results. In either case, you’ll waste traffic and potentially implement changes that will fail.
Before testing more than two variations, you really need to calculate the required sample size. If your traffic volume simply can't support reaching significance within two to three weeks, reduce the amount of variations or perhaps reconsider the test design altogether.
Most brands win by running fewer, more specifically targeted tests that produce clear insights, then iterate, rather than splitting traffic across many variants, spreading it too thin, hoping to get lucky.
AI Shortcut: Before launching any multi-variant test, use an AI tool to sanity-check your sample size requirements.
Prompt example: "My site gets 15,000 weekly sessions on the product page I want to test. Current conversion rate is 2.8%. I want to detect a 15% relative lift at 95% confidence and 80% power. How many variations can I realistically test while reaching significance in 2-3 weeks?"
This takes thirty seconds and can save you from running a doomed experiment.
Practical Framework: When To Go Beyond Two Variations
Here’s decision framework you can use before adding variations to any test:
Make two-variant A/B testing your default. Only test more than two variations when you have enough traffic to reach significance in a reasonable amount of time. Two variations with clear results will always be better than four variations with ambiguous signals.
Calculate the required sample size before testing. If you plan on launching more than one variation at the same time, protect your statistical power by knowing exactly what's required before you commit your valuable traffic.
Cap your variants when traffic is moderate. If you have limited traffic, perhaps keep it to a maximum of three. Your control plus two variations. This will keep you from spreading data too thin while still allowing some exploration.
Use multi-variant testing for refinement, rather than exploration. Use three or more variants only after you've successfully validated your core idea and are ready to optimize the best direction. Multi-variant testing works best when you're refining a proven winner, not when you're searching for product-market fit on a page element without much backing data.
Your variants must be directional, not random. Keep one main hypothesis, but vary a single lever for each version. Clarity versus trust versus urgency, for example. The goal is for every result to answer why, not just what. When you test random variations, attribution is almost impossible to detect, even if you find a clear winner.
AI Shortcut: After completing a multi-variant test, use AI to extract deeper insights from your results.
Prompt example: "Here are my test results: Control converted at 3.1%, Variation A (trust-focused) at 3.4%, Variation B (urgency-focused) at 2.9%, Variation C (specificity-focused) at 3.8%. What does this pattern suggest about my audience's decision-making priorities, and what should I test next?"
AI can help you identify patterns across variations that might not be immediately obvious and accelerate your iteration planning.
The Copywriting Parallel
You can apply the same logic to copy testing. When testing headlines or value proposition messaging, creating effective hooks for specific angles will help you understand what resonates with users, as well as what doesn’t. A single version limits the learning you can extract from your test.
But, and this is critical, running a copy test with five headline variations will only work if you have enough traffic. If not, you're just wasting your time and budget. You'll end the test with five partial signals and zero concrete conclusions.
The principle stays constant across all types of tests: more variations will require more traffic. If you don’t have the traffic, reduce your variations.
AI Shortcut: Need to generate multiple headline variations quickly? Use AI to create angle-specific options from your core value proposition.
Prompt example: "My product is a premium dog food subscription. Generate three headline variations for my landing page: one emphasizing health benefits, one emphasizing convenience, and one emphasizing cost savings versus competitors. Keep each under 10 words."
This helps you create meaningfully different variations faster while maintaining strategic focus.
The Bottom Line
There’s nothing inherently wrong with multi-variant testing, but it is context-dependent. When your traffic can support it and your hypotheses are on point, testing three or more variations can reduce learning cycles and produce richer insights. When you lack adequate traffic or you decide to base your tests on vague hypotheses, you should expect useless noise, extended timelines, and eroded confidence in each of your results.
"Experimentation isn't about more options. It's about less uncertainty," says Fernandes.
The real discipline of experimentation lies in matching your test design to your realistic constraints. For most e-comm brands, that translates to prioritizing sequential learning over parallel guessing, depth over width, and statistical rigor over ambitious but blind test designs.
Two sharp variations beat four weak guesses every single time. Base your experimentation program on that principle, and you'll find yourself generating much more reliable insights with much less traffic wasted.



